개요
jdbc와 r2dbc Connection Pool에 대한 고찰과 어떠한 경우에 무엇을 선택해야 할지에 대한 고민을 담은 글입니다. 예전 글에서도 Connection Pool을 정리한 적(Connection Pool이란?)이 있었기 때문에 개념과 사용이유만 짚고 가겠습니다. 직접 구현해본 경험은 없었으므로 간단한 CRUD 예제 프로젝트로 학습했던 내용을 정리했습니다.
connection pool 개념
- 웹 컨테이너(WAS)가 실행되면서 DB와 미리 연결을 해놓은 객체들을 Pool에 저장해 둔다.
- 이후 클라이언트 요청이 오면 Connection을 빌려주고, 처리가 끝나면 다시 Connection을 반납받아 Pool에 저장하는 방식
사용이유
db에 직접 연결해서 처리하는 경우 드라이버를 불러오고 Connection 객체를 받아옵니다. 때문에 매번 사용자가 요청할 때마다 드라이버를 불러오고 Connection 객체를 생성하여 연결하고 종료하기 때문에 성능저하로 이어집니다.
- 반복되는 비용과 시간으로 OOM(Out Of Memory)이 발생할 우려가 높습니다.
- DB의 TCP통신 - 데이터 전송 전, 정확한 전송 보장 : 3 Way-handshake / 데이터 전송 종료 후 리소스 정리 : 4 Way-handshake
위와 같은 문제를 해결하기 위해 커넥션풀을 사용함으로써 서버의 성능을 높여주고 사용자의 대기시간을 줄여줄 수 있습니다.
동시 접속자가 많을 경우
- Pool에서 미리 생성된 Connection을 제공하고 Connection이 없을 경우는 사용자는 Connection이 반환될 때까지 순서대로 대기상태에서 기다립니다.
- WAS에서 Connection Pool을 크게 설정하면 메모리 소모가 큰 대신 사용자의 대기시간이 줄어들지만, 반대로 Connection Pool을 적게 설정하면 사용자의 대기시간이 길어집니다.
커넥션 풀 개수 설정
대부분의 was의 커넥션 풀의 default 값은 10~20입니다.
- Hikari CP의 공식 문서 : PoolSize = Tn × ( Cm - 1 ) + 1
-
- Tn : 전체 Thread 개수
- Cm : 하나의 Task에서 동시에 필요한 Connection 수
- -1 : 마지막 Connection이 필요한 Sub Transaction에 대한 처리
- +1 : Connection 1개가 마지막 Sub Transaction을 해결할 수 있게 해 줍니다.
-
- mySQL 공식문서 : 600명의 유저를 대응하는데 15~20개의 Connection Pool이 필요
- 예제 프로젝트에서는 기본적인 crud API를 사용할 때 10개의 커넥션 만으로도 3000명의 사용자를 원활히 처리할 수 있었습니다.
스레드 개수 설정
Connection의 개수를 설정할 때 스레드의 개수는 일반적으로 Connection의 개수보다 10~20개를 많게 설정합니다. 스레드의 개수가 Connection의 개수보다 많아야 하는 이유는
- Connection을 사용하는 주체인 Thread의 개수보다 Connection Pool의 크기가 크다면 사용되지 않고 남는 Connection이 생겨 메모리의 낭비가 발생합니다.
- 서버에 대한 모든 요청이 DB에 접근하는 것은 아니기 때문입니다.
- 과도한 스레드는 Context Switching의 교체 비용 때문에 성능저하로 이어집니다.
커넥션 풀 개수 설정
위의 공식보다 좀 더 많은 pool size를 지정할 수도 있으며, 결국에는 현재 프로젝트에서 가장 적합한 Connection Pool의 개수를 성능/부하 테스트를 통해서 가장 적절한 값을 찾아야 합니다.
JDBC와 R2DBC 비교
JDBC는 모든 DBMS를 자유롭게 사용할 수 있지만 R2DBC는 지원되는 DBMS 드라이버가 많지 않았습니다.
- JDBC는 쿼리마다 Thread를 만들어서 수행해야 하기 때문에 자원이 비효율적이라, 그것을 DBCP로 풀어낸 것인데(Tomcat, Hikari ... 등)
- Reactive 하다는 것은 Async 한 Task들을 EventLoop방식으로 Queue에 쌓아두고, Thread를 보다 효율적으로 사용하는 것으로 자원 및 성능 둘 다 강점이 있습니다.
- webflux를 사용했을 때 효과가 좋은 상황은 API에 대한 트래픽이 많은 경우
- R2DBC를 사용해서 API 에 대한 요청은 처리할 수 있지만, JPA의 기능은 지원하지 않는다고 합니다.
- JDBC는 연결당 스레드를 사용하는 반면 R2DBC는 더 적은 스레드를 사용
R2DBC 지원 드라이버
- R2dbc-h2: H2 드라이버
- R2dbc Mariadb: Mariadb 드라이버
- R2dbc MSSQL: Microsoft SQL Server 로컬 드라이버
- R2dbc mysql: mysql 드라이버
- R2dbc PostGRE: PostgreSQL 드라이버
JDBC
- Blocking 동작
R2DBC
- Non Blocking 동작
- 적은 스레드로 동시 처리를 제어
논블로킹 ≠ 비동기
- 논블로킹에서 응답이 느리게 돌아온다면 API는 에러와 함께 복귀하고 다른 행동을 하지 않는 반면 비동기 환경에서는 API는 항상 즉시 복귀하지만 응답은 늦게 돌아오기도 합니다.
- 즉, 논블로킹은 함수가 호출되어 있어도 제어권이 반환되었으므로 다음 작업을 실행하고, 비동기에서는 함수호출을 스택에 남겨두고 함수호출을 대신하여 작업이 다른 스레드에서 계속 이어집니다.
- 비동기는 병렬처리에 가깝고, 논블로킹은 폴링(주기적인 확인)에 가깝습니다.
| 동기 | 비동기 | blocking | non-blocking |
| 함수 x가 함수 y를 호출한 뒤, x에서 y의 리턴값을 확인하기 위해 계속 체크합니다. | 함수 x가 함수 y를 호출할 때 콜백 함수를 함께 전달, 이후 x는 다른 작업을 수행(다른 스레드 점유)하며 y의 작업종료 유무는 체크하지 않습니다. | x가 y를 호출할때 y는 자신의 작업을 모두 마칠 때까지 x의 제어권을 가집니다. x는 제어권이 없으므로 실행을 멈춥니다. | x가 y를 호출할때 제어권을 즉시 return 받는다. 호출이후에는 주기적으로 결과값을 체크하며 자신의 코드 진행(다른 스레드 점유 X) |
- blocking시 해당 Thread의 제어권이 넘어가서 대기 중일 때 다른 Thread를 동작시켜 비동기적으로도 수행할 수 있지만 위에서 설명드린 과도한 스레드는 Context Switching 때문에 성능저하를 유발하기 때문에 주의해야 합니다.
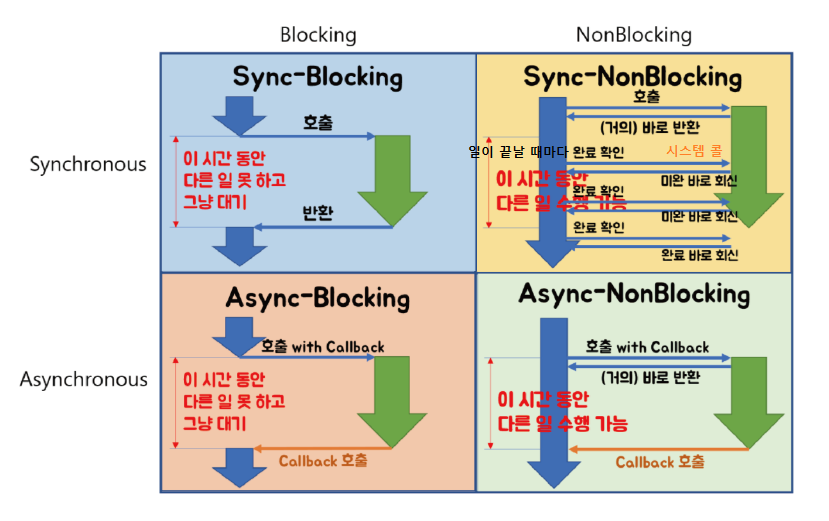
- 위 그림과 같이 동기&비동기 + 블로킹&논블로킹을 조합해서 사용하는 방식도 있습니다.
예제 프로젝트 목적
- r2dbc와 jdbc(DDD Aggregate Root 패턴 촉진, jpa에 대한 더 간단한 대안) 차이
- 성능테스트(동시접속자 수 생각해서 적용) & 부하테스트
- 기본적인 CRUD를 만들어서 측정
- deadlock을 피하기 위한 방법
https://dev.to/kamalhm/configuring-connection-pooling-with-spring-r2dbc-ho6
테스트 진행 과정
- r2dbc & jdbc connection의 특징, 장/단점, 각각을 비교하며 진행
- 성능/부하테스트 → Jmeter를 활용했습니다.
- 데이터가 많을 경우 and 적을 경우 and 서버 비즈니스 로직이 복잡할 경우는?
- 위의 상황 중 가장 자주 사용되고 많은 트래픽이 발생하는 select를 중심으로 테스트 진행
- 커넥션풀과 스레드의 개수에 따라서 어떤 변화가 발생하는지 테스트
- 앞선 데이터의 결과를 토대로 어떠한 경우에 jdbc OR r2dbc를 선택해야 하는지
- 커넥션풀의 개수를 늘리면 오히려 max값이 증가했습니다.(서버에 부하가 발생하기 때문)
- api응답시간은 jdbc가 압도적으로 빠름
- 하지만 서버에서 처리하는 양을 기준으로 본다면 r2dbc가 우월함
- 결국 동시성을 생각한다면 r2dbc(cpu와 메모리사용량도 r2dbc가 작다.)가 우월합니다.
- 커넥션풀의 max값을 늘리면 서버의 처리량도 증가하는것을 확인할 수 있었습니다.
- r2dbc-pool 라이브러리사용(pool사이즈만 직접 yaml에서 조정)
정리가 길어지는 것 같아 테스트 결과물과 yaml 설정은 2편에서 이어가겠습니다.
'CS' 카테고리의 다른 글
| Nginx Proxy vs API Gateway(Part. 1) (0) | 2023.12.09 |
|---|---|
| Connection Pool 테스트와 고찰(2) (0) | 2023.11.07 |
| Cold Stream vs Hot Stream 이란? (1) | 2023.10.31 |
| API 헬스체크 (0) | 2023.08.17 |
| Connection pool (0) | 2022.12.06 |