1. jdbc yml 설정
1) connectionTimeout (default : 30000 (30 seconds))
- 클라이언트가 Pool에 Connection을 요청하는데 기다리는 최대시간을 설정
- 즉 db 서버에 연결할 때까지의 연결 대기 시간, 최대시간이 지나면 ConnectionTimeoutException이 throw 됩니다.
- 이 경우 connection-timeout 값을 늘려주거나, maximum-pool-size를 늘려줘야 합니다.
2) maximunPoolSize (default : 10)
- Pool에 보관가능한 최대 Connection 개수 설정
3) minimumIdle (default : maximumPoolSize와 동일)
- Pool에서 보관가능한 최소 Connection 개수 설정
- minimum-idle을 설정할 경우 maximum-pool-size만큼 생성하지 않고 minimum-idle개수만큼 생성
4) idleTimeout (default : 600000 (10분))
- 작업을 진행하지 않는 Connection을 유지하는 시간이며, Pool에서 유지하는 최소 Connection 수는 minimumIdle이 기준이며 나머지는 연결해제
5) maxLifeTime (default : 1800000 (30분))
- Connection이 Connection Pool에서 머무를 수 있는 최대시간, Pool 전체가 아닌 Connection 별로 적용되며 사용 중이지 않은 Connection만 제거 대상이다.
6) readOnly (default : false)
- Pool에서 얻은 Connection이 기본적으로 readOnly인지 지정하는 설정
7) connectionTestQuery (default : none)
- 데이터베이스 연결이 활성화되어 있는지 확인하기 위해 Pool에서 Connection을 제공하기 전에 실행되는 쿼리
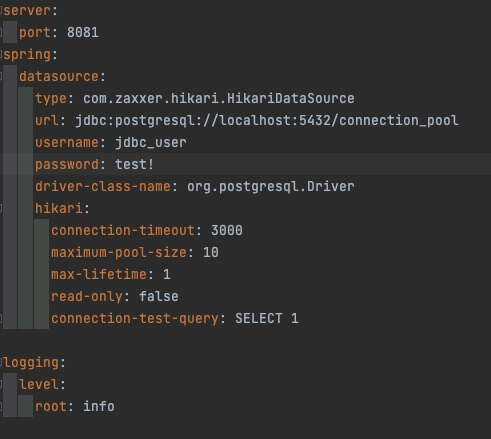
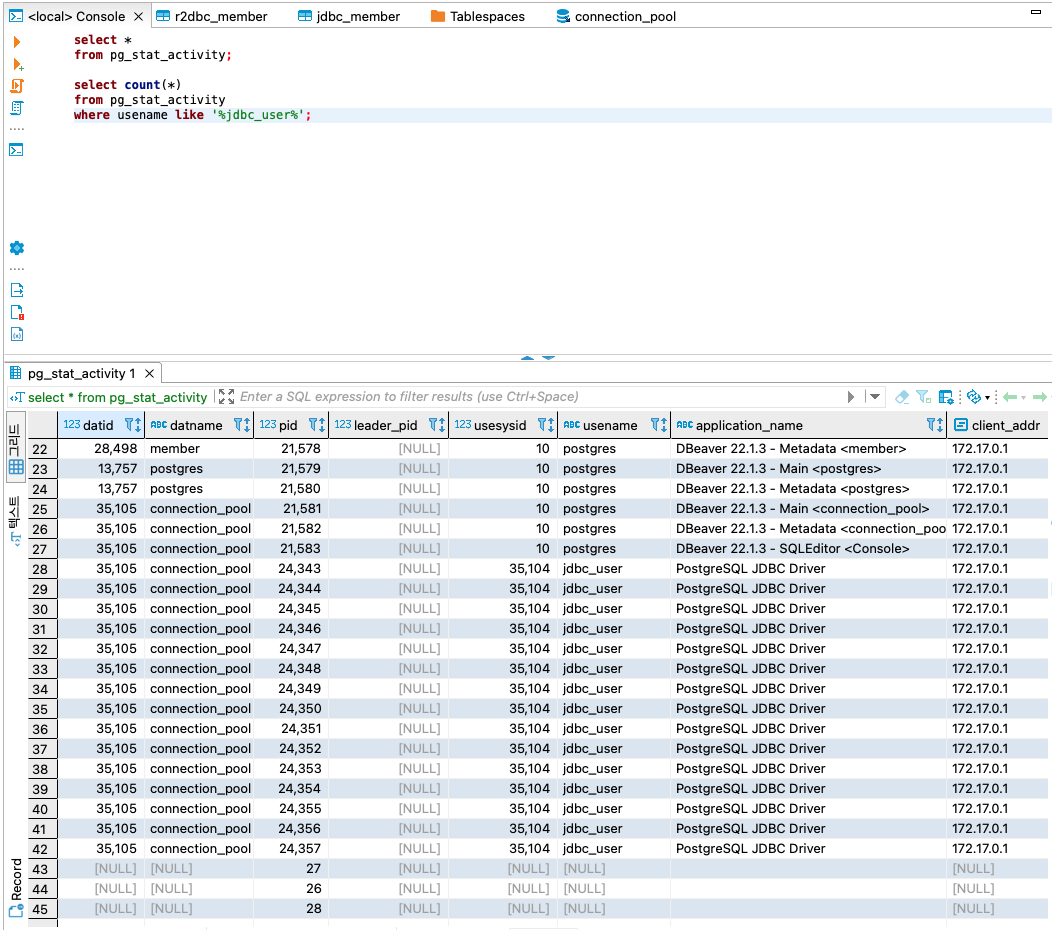

- pg_stat_activity에서 yaml에서 설정한 커넥션의 개수만큼 db에서도 15개의 커넥션이 생성된 것을 확인해 볼 수 있습니다.
- 만약 yml에서 pool-size를 지정하지 않는다면 default size는 10입니다.
2. r2dbc pool yml 설정
- initial-size(default : 10) : 초기 Pool 크기
- max-idle-time(default : 1800000 (30분)) : Pool에서 연결의 최대 대기 시간입니다. 기본값은 30분입니다.
- max-size(default : 10) : 최대 Pool 크기
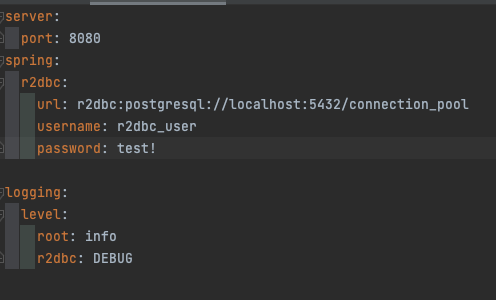
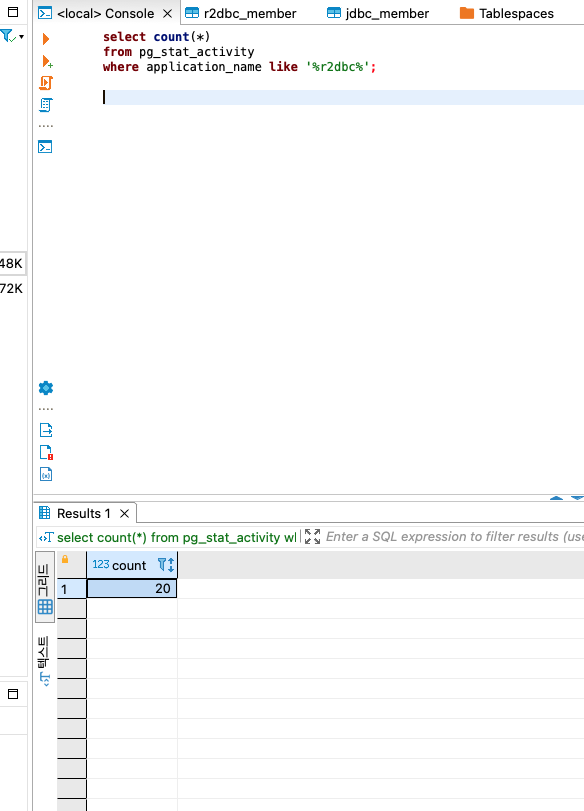

- max_connections에서는 현재 db의 최대 pool size를 확인할 수 있으며 max pool size의 변경은 postgresql.conf에서 가능했습니다.
Thread 설정(yaml)
undertow:
threads:
io: 8 // 작업자에 대해 생성할 I/O 스레드 수입니다. 기본값은 사용 가능한 프로세서 수에서 파생됩니다.
worker: 200 // 작업자 스레드 수입니다. 기본값은 I/O 스레드 수의 8배입니다.
- 톰캣은 사용자 요청이 오면 읽기 - 처리 - 쓰기 모두 동일한 스레드에서 처리되는데 Undertow의 읽기 쓰기 작업은 io thread가, 처리 작업은 worker 스레드가 담당하게 됩니다.
- 스프링부트에서 언더토우의 IO스레드와 WORKER스레드의 기본값은 IO스레드는 Core만큼, WORKER스레드는 IO스레드의 8배입니다.
- WAS는 DB나 API호출 같은 블로킹 작업들이 많기 때문에 IO스레드는 core * 2로 하더라도 WORKER스레드는 많이 필요합니다.
- 일반적으로 톰캣의 max-threads를 참고하여 주면 될 듯합니다. 물론 서버 성격에 따라 다르기 때문에 상황에 맞게 설정해야 합니다.
- 블로킹 작업이 별로 없는 서버이고 요청이 빈번하거나 요청과 응답값의 데이터가 크다면 IO스레드를 조금 더 늘려주고 WORKER스레드를 조금 더 줄여도 됩니다.
- 만약 설정을 자주 변경하기 어렵다면 처음부터 넉넉하게 설정해도 무관합니다. worker 스레드를 2로 설정하면 해당 서버에 대한 동시 요청을 2개씩 밖에 못 합니다.
- 또한 부하테스트의 결과가 동일하게 나오는 현상도 있었습니다. 이는 undertow의 thread와 연관이 있었던 걸로 예상합니다.(undertow는 최소 24 개의 스레드, 최대 60 개의 스레드를 가진다)
- Solution : thread와 pool size를 늘려준다면 임계점을 높일 수 있을 것 같다.
Jmeter를 활용한 테스트 결과
부하테스트
- r2dbc
- 10 pool → 10000 thread → 10000건에 가까워질경우 부하
- 20 pool → 5000 thread (10번 반복) 6번째 루프에서 4000 thread가 넘어갈 때 부하
- jdbc
- 10 pool → 10000 thread 7000건에 가까워질경우 부하
- 20 pool → 5000 thread (10번 반복) 2번째 루프에서 4000 thread 넘어갈때 부하
- 현재 프로젝트의 임계점은 최대 7~9000 사이로 확인되며 로컬 pc의 한계로 더 많은 케이스로 테스트를 진행하기엔 힘들었습니다.
- 부하의 임계치는 유의미한 결과는 아니였지만 r2dbc가 조금은 높은 걸로 확인됐습니다. 예상으로는 r2dbc는 문제없이 진행될줄 아았는데 테스트 진행 환경에 문제가 있었던것 같습니다.
성능테스트
성능테스트에서는 유의미한 결과를 나타냈으며 r2dbc가 동시성에 있어 확실한 우위를 보였습니다.
1. r2dbc
- 5000명(pool 20개) → throughput(분당 처리량) : 63,264.445, deviation(표준편차) : 123, average(평균응답시간) : 43ms
- 5000명(pool 10개) → throughput : 53,212.534, deviation : 179, avg : 69ms
- 100명 20 반복(pool 20개) throughput : 120,481.928, deviation:16, avg : 4ms
- 100명 10 반복(pool 10개) throughput : 118,343.195, deviation:9, avg : 4ms
- 1000명 10반복(pool 10개) → throughput : 169,300.226, deviation:88, avg : 263ms
- 1000명 20 반복(pool 20개) throughput: 162,315.704, deviation:99, avg : 269ms
2. jdbc
- 5000명(pool 10개) → throughput : 20,882.64, deviation : 2262, avg : 1562ms
- 5000명(pool 20개) → throughput : 18,850.141, deviation : 2338, avg : 1882ms
- 100명 20반복(pool 20개) throughput : 49,342.105, deviation:35, avg : 1002ms
- 100명 20반복(pool 10개) throughput : 63,224.447, deviation:526, avg : 869ms
- 1000명 20반복(pool 10개) → throughput : 58,024.273, avg : 942ms
- 1000명 20반복(pool 20개) throughput: 57,689.534, deviation:342, avg : 931ms
문제상황
- 동일 DB에 Connection Pool을 다량 보유한 여러 요청들이 접근할 경우 생성된Connection Pool의 개수가 너무 많아지는 경우가 발생했습니다.
- 100개를 넘어가는 커넥션풀을 만들었을 때 에러 발생
- 발생원인 : postgresql.conf 파일에 정의된 max_connections(pool size)를 초과
- jmeter 측정 시 네트워크 상태와 로컬 pc의 상태가 성능테스트에 영향을 끼쳐 여러 번의 테스트를 진행해야 했습니다.
- 실제 서버에 대한 테스트는 CLI에서 원격 PC설정을 이용해 테스트를 진행하는 방식이 존재했습니다.
결론
- 대략 500명 정도의 사용자는 성능 테스트를 진행했을 때 JDBC가 응답시간과 서버의 처리량이 R2DBC에 비해 성능이 뛰어났고, 500명 이상의 테스트에서는 R2DBC의 성능이 뛰어났습니다.
- 앞선 결과로 R2DBC는 트래픽이 높아지거나 많은 사용자들이 접근하는 서비스일 때 유리하며, 이때 JDBC에 비해 높은 서버처리량과 빠른 응답시간을 확인할 수 있었습니다.
- 물론 실무와는 차이가 있는 환경이고 개인 PC로 테스트를 진행했기 때문에 실무와 비교해서 엄청난 의미가 존재하는 결과는 아니라고 생각합니다. 하지만 직접 학습한 내용을 구현해보고 나름의 결과를 얻었기에 만족스러웠습니다.
TIP : Jmeter로 실제 운영서버를 테스트할 경우에는 운영서버로 성능/부하테스트를 진행하면 안 됩니다.
이상으로 Connection Pool에 대한 나름의 대장정이 정리된 것 같습니다. 학습한 내용을 바탕으로 실제 구현해 보니 많은 도움이 되었고 앞으로도 더 좋은 포스팅을 하기 위해 노력해야 할 것 같습니다.. 부족한 포스팅이기에 잘못되거나 보충사항이 있으면 조언해 주시면 감사하겠습니다~
'CS' 카테고리의 다른 글
| Nginx Proxy vs API Gateway(Part. 2) (0) | 2023.12.20 |
|---|---|
| Nginx Proxy vs API Gateway(Part. 1) (0) | 2023.12.09 |
| Connection Pool 테스트와 고찰(1) (0) | 2023.11.07 |
| Cold Stream vs Hot Stream 이란? (1) | 2023.10.31 |
| API 헬스체크 (0) | 2023.08.17 |