k8S Pod Lifecycle 정의
파드는Pending 단계에서 시작해서, 기본 컨테이너 중 적어도 하나 이상이 OK로 시작하면 Running 단계를 통과하고, 파드의 컨테이너가 실패로 종료되었는지 여부에 따라 Succeeded 또는 Failed 단계로 이동합니다.
파드가 실행되는 동안, kubelet은 오류를 처리하기 위해 컨테이너를 다시 시작하기도 합니다 . 파드 내에서, 쿠버네티스는 다양한 컨테이너 상태를 추적하고 파드를 다시 정상 상태로 만들기 위한 조치를 결정합니다.
Kubelet은 Kubernetes 노드에서 실행되는 에이전트로, 클러스터의 마스터와 노드 간의 통신역할을 수행하며 노드 내의 모든 파드 상태를 감시하고, 파드의 요청에 따라 컨테이너를 실행 및 관리합니다. 또한 클러스터에 등록되고 마스터와의 상태를 주기적으로 보고하여 자신의 상태를 업데이트하며 클러스터의 가용성과 성능을 향상시키는 기능을 수행합니다.
파드는 파드의 수명 중 한 번만 스케줄 됩니다. 파드가 노드에 스케줄(할당)되면, 파드는 중지되거나 종료될 때까지 해당 노드에서 실행됩니다.
파드의 수명
개별 애플리케이션 컨테이너와 마찬가지로, 파드는 비교적 임시(계속 이어지는 것이 아닌) 엔티티로 간주됩니다.
파드가 생성되고, 고유 ID(UID)가 할당되고, 종료(재시작 정책에 따라) 또는 삭제될 때까지 남아있는 노드에 스케줄 됩니다.
만약 노드가 종료되면, 해당 노드에 스케줄된 파드는 타임아웃 기간 후에 삭제되도록 스케줄 됩니다. 또한 파드는 자체적으로 복구하지 않습니다.. 파드가 노드에 스케줄된 후에 해당 노드가 실패하면, 파드는 삭제처리 됩니다.
마찬가지로, 파드는 리소스 부족 또는 노드 유지 관리 작업으로 인해 축출되지 않습니다. 쿠버네티스는 컨트롤러라 부르는 하이-레벨 추상화를 사용하여 상대적으로 일회용인 파드 인스턴스를 관리하는 작업을 처리합니다.
파드의 단계
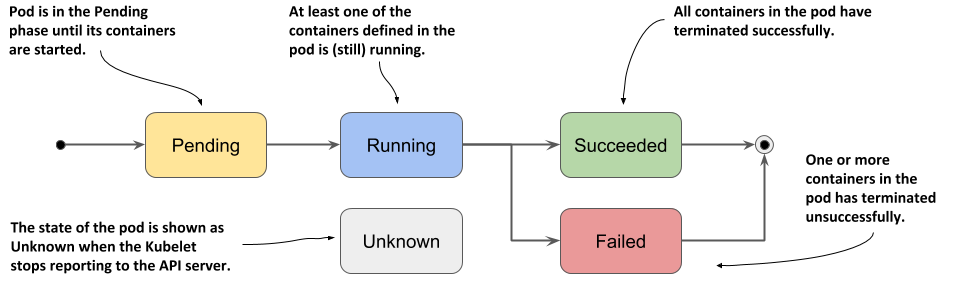
- 파드의 status 필드는 phase 필드를 포함하는 PodStatus 오브젝트로 정의됩니다.
- 파드의 phase는 파드가 라이프사이클 중 어느 단계에 해당하는지 표현하는 간단한 수준의 요약입니다.
phase에 가능한 값은 다음과 같습니다.
| Pending | 파드가 쿠버네티스 클러스터에서 승인되었지만, 하나 이상의 컨테이너가 설정되지 않았고 실행할 준비가 되지 않았다. 여기에는 파드가 스케줄되기 이전까지의 시간 뿐만 아니라 네트워크를 통한 컨테이너 이미지 다운로드 시간도 포함된다. |
| Running | 파드가 노드에 바인딩되었고, 모든 컨테이너가 생성되었다. 적어도 하나의 컨테이너가 아직 실행 중이거나, 시작 또는 재시작 중에 있다. |
| Succeeded | 파드에 있는 모든 컨테이너들이 성공적으로 종료되었고, 재시작되지 않을 것이다. |
| Failed | 파드에 있는 모든 컨테이너가 종료되었고, 적어도 하나 이상의 컨테이너가 실패로 종료되었다. 즉, 해당 컨테이너는 non-zero 상태로 빠져나왔거나(exited) 시스템에 의해서 종료(terminated)되었다. |
| Unknown | 어떤 이유에 의해서 파드의 상태를 얻을 수 없다. 이 단계는 일반적으로 파드가 실행되어야 하는 노드와의 통신 오류로 인해 발생한다. |
- 현재 구동중인 파드의 생명 주기는 다음 명령어로 확인할 수 있습니다. kubectl describe pods <파드이름>
- <파드이름> 을 제외하고 명령어를 입력하면 모든 파드에 대한 정보가 나옵니다.
파드의 조건
파드는 하나의 PodStatus를 가지며, 그것은 파드가 통과했거나 통과하지 못한 조건에 대한 PodConditions 배열을 가집니다.
- PodScheduled: 파드가 노드에 스케줄
- ContainersReady: 파드의 모든 컨테이너 준비
- Initialized: 모든 초기화 컨테이너가 성공적으로 시작
- Ready: 파드는 요청을 처리할 수 있으며 일치하는 모든 서비스의 로드 밸런싱 풀에 추가
| type | 이 파드 조건의 이름 |
| status | 가능한 값이 "True", "False", 또는 "Unknown"으로, 해당 조건이 적용 가능한지 여부를 나타낸다. |
| lastProbeTime | 파드 조건이 마지막으로 프로브된 시간의 타임스탬프이다. |
| lastTransitionTime | 파드가 한 상태에서 다른 상태로 전환된 마지막 시간에 대한 타임스탬프이다. |
| reason | 조건의 마지막 전환에 대한 이유를 나타내는 기계가 판독 가능한 UpperCamelCase 텍스트이다. |
| message | 마지막 상태 전환에 대한 세부 정보를 나타내는 사람이 읽을 수 있는 메시지이다. |
컨테이너 프로브(probe)
프로브는 컨테이너에서 kubelet에 의해 주기적으로 수행되는 진단(diagnostic)입니다. 진단을 수행하기 위해서, kubelet은 컨테이너에 의해서 구현된 핸들러를 호출합니다.
핸들러에는 다음과 같이 세 가지 타입이 있습니다.
- ExecAction은 컨테이너 내에서 지정된 명령어를 실행합니다. 명령어가 상태 코드 0으로 종료되면 진단이 성공한 것으로 간주
- TCPSocketAction은 지정된 포트에서 컨테이너의 IP주소에 대해 TCP 검사를 수행합니다. 포트가 활성화되어 있다면 진단이 성공한 것으로 간주
- HTTPGetAction은 지정한 포트 및 경로에서 컨테이너의 IP주소에 대한 HTTP GET 요청을 수행합니다. 응답의 상태 코드가 200 이상 400 미만이면 진단이 성공한 것으로 간주
각 probe는 다음 세 가지 결과 중 하나를 가집니다.
- Success: 컨테이너가 진단을 통과
- Failure: 컨테이너가 진단에 실패
- Unknown: 진단 자체가 실패하였으므로 아무런 액션도 수행되면 안됨
kubelet은 실행 중인 컨테이너들에 대해서 선택적으로 세 가지 종류의 프로브를 수행하고 그에따라 반응합니다.
- livenessProbe: 컨테이너가 동작 중인지 여부를 나타냅니다. 만약 활성 프로브(liveness probe)에 실패한다면, kubelet은 컨테이너를 죽이고, 해당 컨테이너는 재시작 정책의 대상이 됩니다. 만약 컨테이너가 활성 프로브를 제공하지 않는 경우, 기본 상태는 Success
- readinessProbe: 컨테이너가 요청을 처리할 준비가 되었는지 여부를 나타냅니다. 만약 준비성 프로브(readiness probe)가 실패한다면, 엔드포인트 컨트롤러는 파드에 연관된 모든 서비스들의 엔드포인트에서 파드의 IP주소를 제거합니다. 준비성 프로브의 초기 지연 이전의 기본 상태는 Failure 입니다. 만약 컨테이너가 준비성 프로브를 지원하지 않는다면, 기본 상태는 Success
- startupProbe: 컨테이너 내의 애플리케이션이 시작되었는지를 나타냅니다. 스타트업 프로브(startup probe)가 주어진 경우, 성공할 때까지 다른 나머지 프로브는 활성화되지 않습니다. 만약 스타트업 프로브가 실패하면, kubelet이 컨테이너를 죽이고, 컨테이너는 재시작 정책에 따라 처리됩니다. 컨테이너에 스타트업 프로브가 없는 경우, 기본 상태는 Success
언제 readinessProbe를 사용해야 하는가?
프로브가 성공한 경우에만 파드에 트래픽 전송을 시작하려고 한다면, 준비성 프로브를 지정하면 됩니다.
준비성 프로브가 활성 프로브와 유사해 보일 수도 있지만, 스팩에 준비성 프로브가 존재한다는 것은 파드가 트래픽을 받지 않는 상태에서 시작되고 프로브가 성공하기 시작한 이후에만 트래픽을 받는다는 뜻입니다.
만약 컨테이너가 대량의 데이터, 설정 파일들, 또는 시동 중 마그레이션을 처리해야 한다면, 준비성 프로브를 지정하면 됩니다.
참고: 파드가 삭제될 때 요청들을 흘려 보내기(drain) 위해 준비성 프로브가 꼭 필요한 것은 아니며 삭제 시에, 파드는 프로브의 존재 여부와 무관하게 자동으로 스스로를 준비되지 않은 상태(unready)로 변경합니다. 결과적으로 파드는 파드 내의 모든 컨테이너들이 중지될 때까지 준비되지 않은 상태로 남아 있습니다.
고아 파드
고아 파드(orphaned pods)는 그 부모 오브젝트(예를 들어, ReplicaSet, StatefulSet, DaemonSet 등)가 더 이상 존재하지 않거나 관리하지 않는 상태에서 실행되는 파드를 의미
고아 파드 삭제하기
# 각 워커 노드 접속
# EX : 123.12.123.123
#로그 확인
journalctl -f -u kubectl
#고아 파드 로그 확인
# 예시 : ... orphaned pod "b8a5865c-99b6-4e8c-8adc-ff2962ddb2b1" found, but volume paths are still present on disk : There were a total of 1 errors similar to this. Turn up verbosity to see them.
#b8a5865c-99b6-4e8c-8adc-ff2962ddb2b1 고아 파드 삭제
rm -rf /var/lib/kubelet/pods/b8a5865c-99b6-4e8c-8adc-ff2962ddb2b1
고아 파드 발생의 주요 이유
- 오브젝트 삭제: 부모 오브젝트가 삭제되었지만, 그에 따라 파드가 제대로 삭제되지 않았을 때.
- 설정 오류: ReplicaSet, Deployment 등의 설정에 오류가 있어서, 파드를 제대로 관리하지 못하는 경우.
- 자원 부족: 노드에서 자원(CPU, 메모리)이 부족하여 파드를 제대로 관리할 수 없는 경우.
- API 서버와의 연결 문제: 노드가 쿠버네티스 API 서버와의 연결을 잃었을 때.
- 노드 장애: 노드 자체에 하드웨어적인 문제나 네트워크 문제 등이 발생하여, 파드를 제대로 실행하거나 종료하지 못하는 상황.
- Kubelet 이슈: 노드의 Kubelet 프로세스에 문제가 있어서 파드의 상태를 제대로 갱신하지 못할 때.
- 컨트롤러 버그: Deployment, StatefulSet 등의 컨트롤러에 버그가 있어 파드를 제대로 관리하지 못하는 경우.
- 매뉴얼 인터벤션: 사용자나 관리자가 수동으로 파드 상태를 변경하거나 삭제, 생성 등의 작업을 수행하면서 발생할 수도 있습니다.
출처
https://kubernetes.io/docs/concepts/workloads/pods/pod-lifecycle/
'Kubernetes' 카테고리의 다른 글
| cephObjectGateway(Feat. bucket 생성) (0) | 2024.07.12 |
|---|---|
| Rancher Desktop (0) | 2024.01.06 |